Flexible Streaming Temporal Action Segmentation with Diffusion Models
Jinrong Zhang
🔗 Accepted by ICME25 (to be indexed soon)
Abstract
Temporal distribution shifts occur not only in low-dimensional time-series data but also in high-dimensional data like videos. This phenomenon leads to significant performance degeneration in video understanding methods such as streaming temporal action segmentation. To address this issue, we propose a flexible streaming temporal action segmentation model with diffusion models (FSTAS-DM). By utilizing streaming video clips with varying feature distributions as control conditions, our model can adapt to the shifts and inconsistency of the distribution between the training and testing domains. Additionally, we have introduced a multi-stage conditional control training strategy (MSCC), which enhances the temporal generalization ability of the model. Our method demonstrates commendable performance on datasets like GTEA, 50Salads, and Breakfast.
Introduction
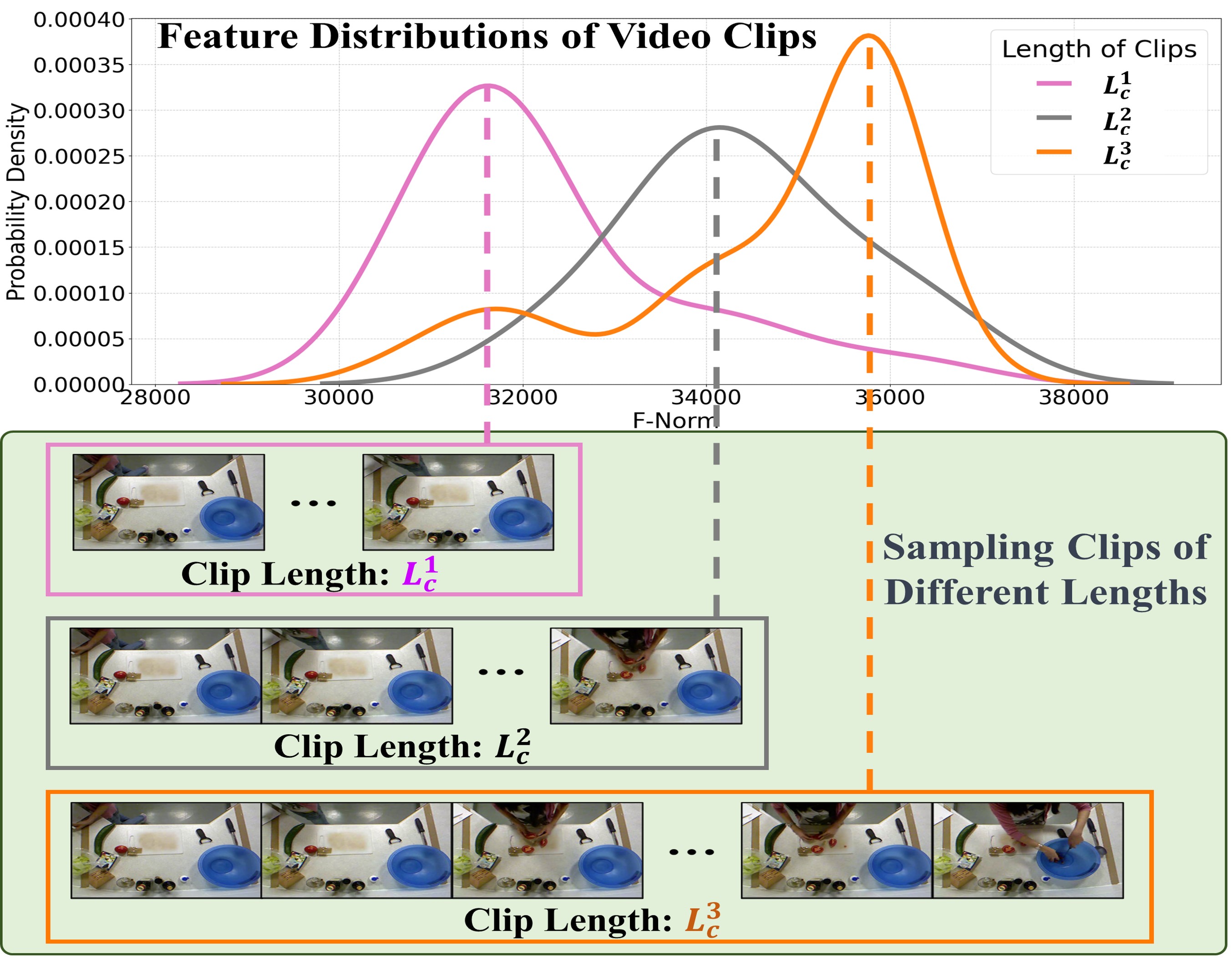
Temporal distribution shifts (TDS) occur widely in the field of times series, refering to the distribution shifts between training and testing domains. This inconsistency hinders achieving optimal performance. Most TDS studies focus on low-dimensional data, such as finance, weather, and electricity usage. However, TDS also occurs in high-dimensional data like videos. To facilitate training, video understanding models are always trained by a fixed number of frames that sample from videos in the whole training process. Those models perform well when tested with the same number of frames, but performance degradation occurred once the number of frames changed. We called this phenomenon video temporal distribution shifts (VTDS) because there are shifts and inconsistencies in video feature distributions between training and testing domains, as shown in Figure. VTDS severely limits the temporal generalization capability of video understanding models, which refers to accurately and stably mapping feature data with previously unseen distributions from feature space to label space. If a model is trained on video clips of the same length, it tends to be trained only on samples with a similar data distribution, significantly limiting the model's application scope.
Streaming temporal action segmentation (STAS) task, which decomposes a full video into a stream of video clips and classifies each frame of every clip in temporal order, is a task significantly affected by VTDS. In practical scenarios, different capture devices provide streaming video clips of varying lengths, and different applications have varying requirements. However, for ease of engineering implementation, current models use the same clip length for both training and testing. When the length of video clips used in testing does not align with the training, the performance of models is substantially decreased. It is VTDS that is consistent with the phenomenon in the STAS task.
To mitigate VTDS, we introduce the diffusion structure into STAS, inspired by DiffAct. Diffusion models, exceling in learning complex and diverse data distributions, are widely used in image generation, style transfer, and time-series tasks. Inspired by this, we propose FSTAS-DM, a flexible streaming temporal action segmentation model with diffusion models. Our model generates predicted labels from noisy data with RGB videos as control inputs. The diffusion structure enables learning diverse distributions and adapting to distribution shifts in the testing domain. We further enhance generalization with a multi-stage conditional control strategy (MSCC), dividing training into stages. In each stage, streaming clips with different feature distributions guide the diffusion process. This stage-by-stage learning helps denoise sequences into final temporal label predictions.
In summary, this paper presents three main contributions: (1) We discover the phenomenon of VTDS in the video understanding field and tackle it by proposing FSTAS-DM. (2) The multi-stage conditional control training strategy we proposed can enhance the temporal generalization ability and significantly reduce the training cost when STAS models are applied to different video clip lengths. (3) The proposed method achieves commendable performance on datatsets like GTEA, 50Salads, and Breakfast.
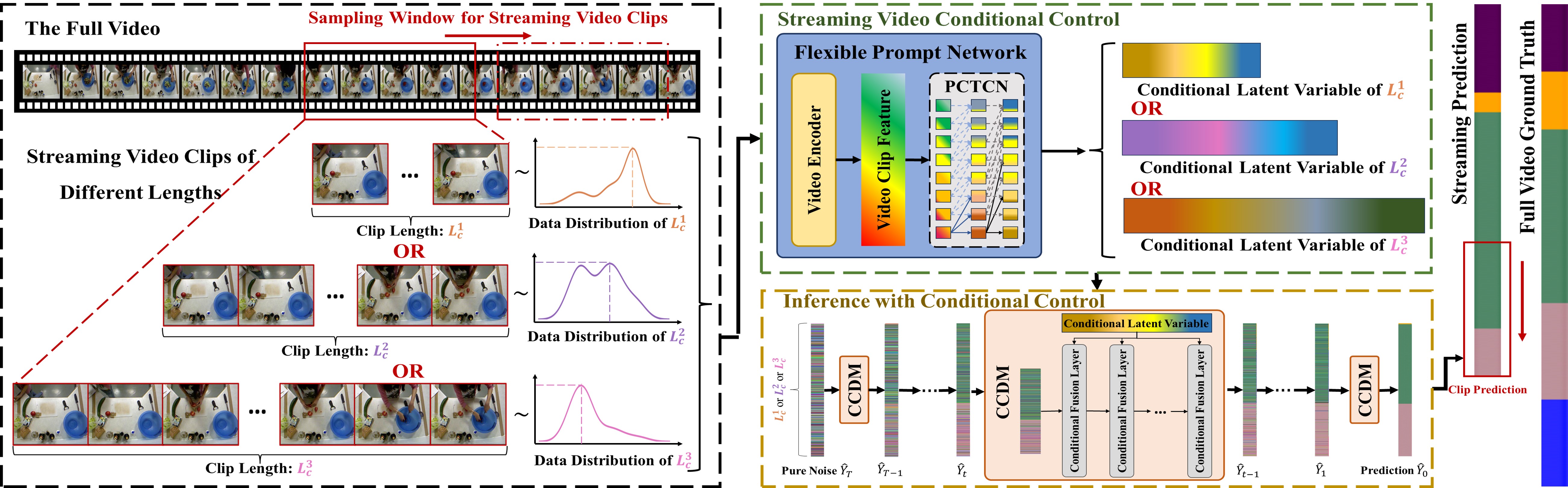
Method
FSTAS-DM consists of a streaming video conditional control process and an inference process with conditional control, as shown in Figure . During the streaming video conditional control process, conditional latent variables
Experiments
The Impact of Video Temporal Distribution Shifts
Figure illustrates the significant impact of VTDS on model performance. We adopt three typical temporal action segmentation models with entirely different structures to STAS, including MSTCN, ASFormer, and DiffAct. We train them on video clip streams with a fixed length of 128 and test them across a variety of clip lengths. It is apparent that VTDS leads to a severe training-testing discrepancy, which means model performance deteriorates as the difference in video clip lengths between training and testing increases. Such performance degradation highlights the inadequate temporal generalization capability of existing temporal action segmentation methods, showing their difficulty in adapting to the altered data distribution caused by VTDS.
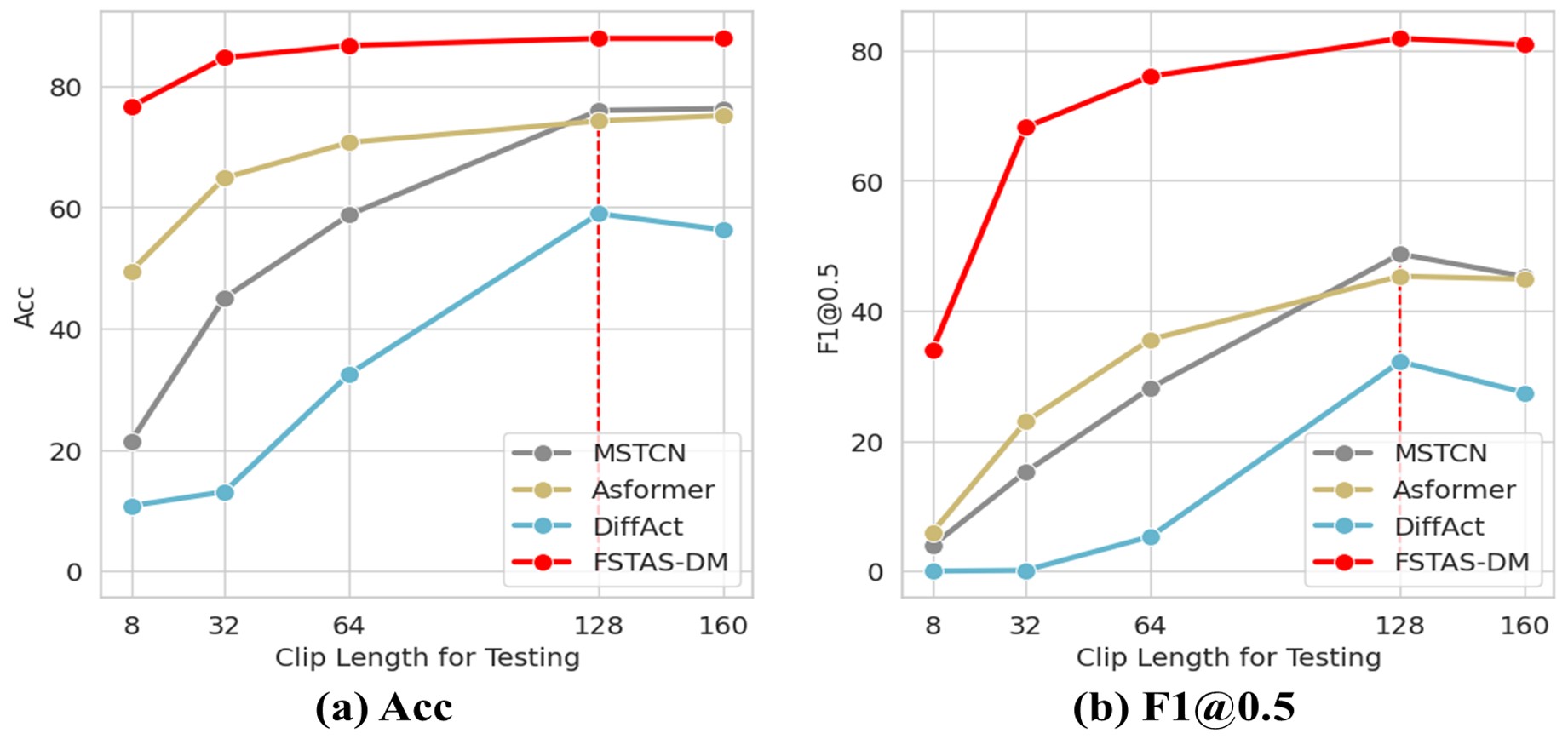
We also compare FSTAS-DM with these three methods. It is evident that FSTAS-DM not only significantly outperforms these three methods in STAS but also greatly mitigates the impact of VTDS.
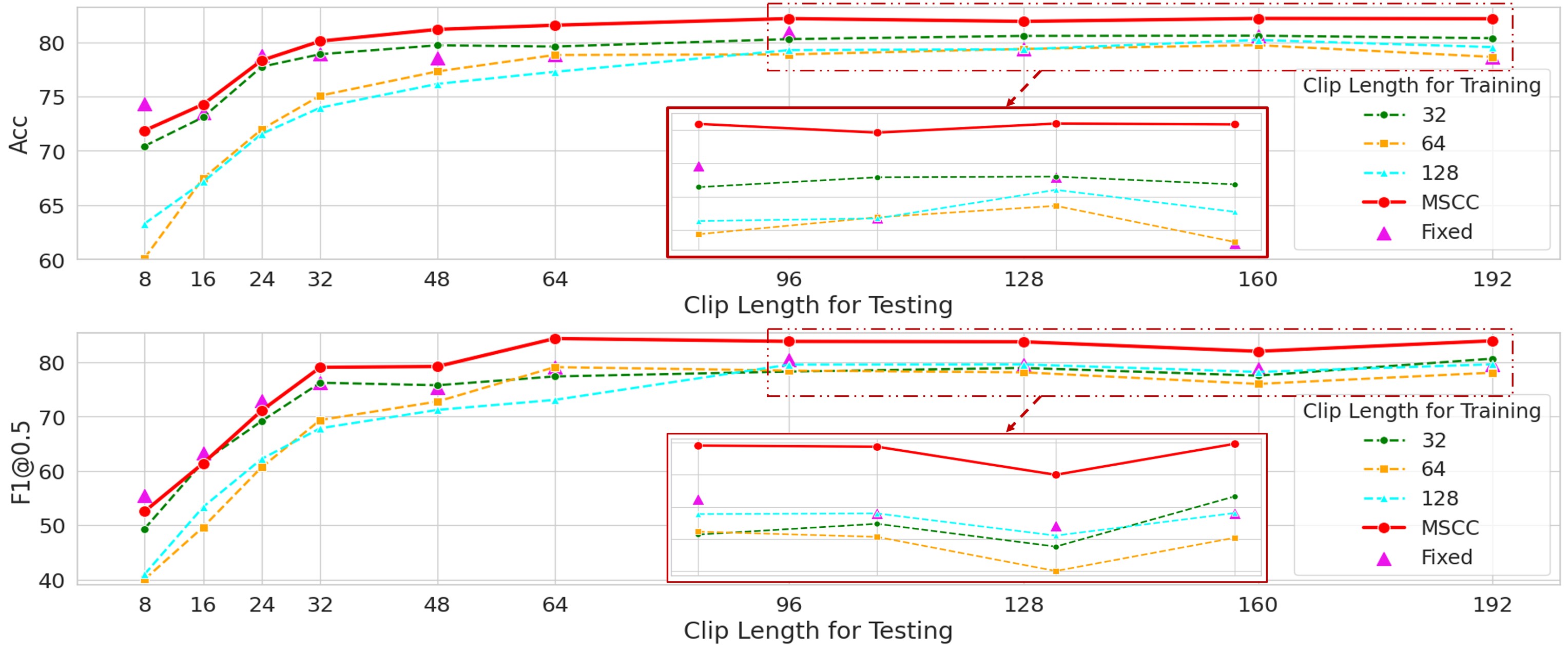
The Temporal Generalization Capability of FSTAS-DM
Figure shows FSTAS-DM's temporal generalization capability. Trained and tested on streaming clips of varying lengths, it outperformed fixed-length models, which struggled with shorter clips. Using MSCC with clip lengths of 32, 64, and 128 improved performance across all lengths. The results demonstrate that FSTAS-DM captures VTDS's impact on data distribution by learning from limited samples.
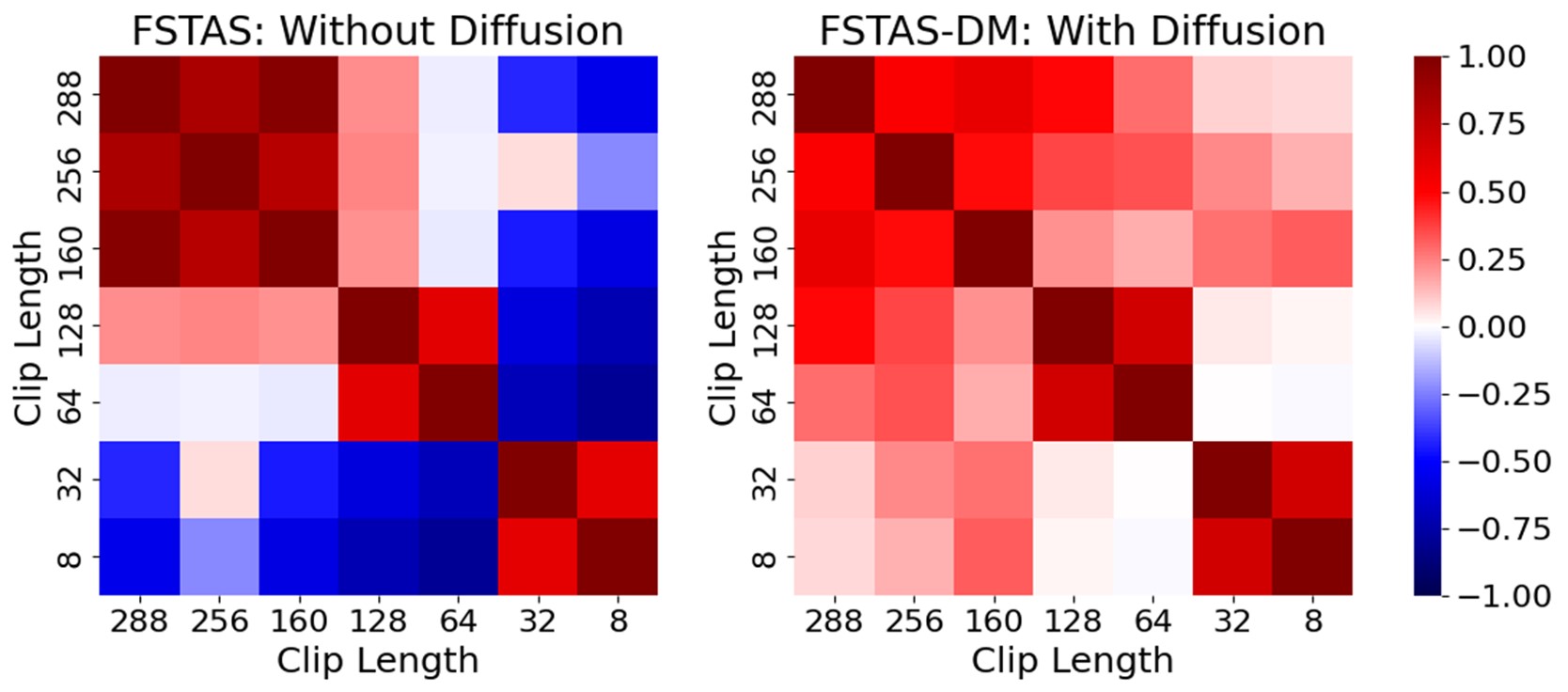
As mentioned, we introduce the diffusion structure into STAS to enhance temporal generalization. Figure shows its impact on streaming video features. STAS aims to map streaming video clips from an undefined data space to a relatively stable label space. To analyze the effect of diffusion on VTDS, we removed the diffusion structure from FSTAS-DM, creating FSTAS. Figure compares the cosine similarity matrices of prediction features for FSTAS-DM and FSTAS. Without diffusion, FSTAS shows significant variance for clips of different lengths, indicating unstable mapping to the label space. With diffusion, prediction feature correlations improve across different clip lengths, demonstrating that the diffusion structure enhances temporal generalization.
Comparison to prior work
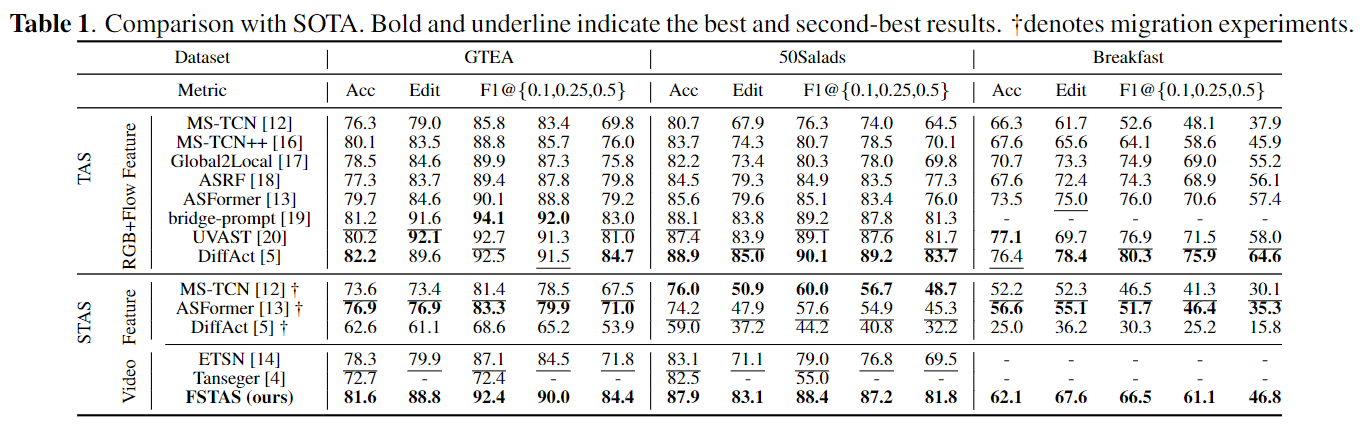
In Table FSTAS-DM is compared with existing TAS and STAS methods. STAS is more challenging than TAS due to limited model view and lack of context. FSTAS-DM achieves competitive results with SOTA TAS methods and outperforms existing STAS methods. On the Breakfast dataset, RGB quality is poorer than in Gtea and 50Salads, leading to suboptimal performance for RGB-only methods. While most TAS methods use multimodal inputs (RGB and optical flow) to compensate for poor RGB quality, FSTAS-DM follows the online STAS design, using only RGB input, resulting in lower performance on Breakfast.
Conclusion
In this paper, we study VTDS using STAS as the foundation and propose FSTAS-DM as a solution. We integrate diffusion architecture into STAS, using streaming video clips with varying feature distributions as conditions for generating action label sequences, significantly improving temporal generalization. Additionally, the proposed MSCC further enhances the model's ability to learn complex distributions. Due to its strong temporal generalization, our method not only boosts performance but also lowers training costs when applying STAS to different video lengths.
Citation
1 | @inproceedings{long2024noisy, |