
I am currently a Ph.D. student in Electronic Information at the School of Computer Science and Technology, Harbin Institute of Technology, Shenzhen , supervised by Prof. Jianlong Wu. Prior to this, I completed seven years of undergraduate and master’s studies at Dalian University of Technology.
My current research interests focus on Multimodal Large Language Models, Multimodal Reasoning, Open World Object Detection and Segmentation, and Video Understanding & Temporal Analysis.
If you’re interested in my research or have any research-related questions, please feel free to contact me via email at zhangjinrong731@gmail.com.
📖 Education
- 2025.09 - 2029.06, Harbin Institute of Technology, Shenzhen
PhD in Electronic Information, School of Computer Science and Technology (Supervisor: Prof. Jianlong Wu) - 2022.09 - 2025.06, Dalian University of Technology
Master in Control Science and Engineering, School of Control Science and Engineering - 2018.09 - 2022.06, Dalian University of Technology
Bachelor in Transportation Engineering, School of Transportation and Logistics
💻 Internship Experience & Programs
- Open World Object Detection & Segmentation: Research Intern, Xiaomi, 2024.03 - 2024.09
- Developed an open-world detection and segmentation large model solution from scratch for the large die casting defect detection business at Xiaomi Automobile Factory. Outperformed SAM2 by achieving a 4.6% increase in AP50 on the proprietary validation set, with a significant >30% performance boost on long-tail categories.
- Published a paper at AAAI based on the experimental research and findings conducted during the internship.
- Complex Video Object Segmentation: CVPR Workshop, 5th PVUW Challenge, 2026.02 - 2026.03
- The 1st Winner for 5th MOSE Challenge: Proposed tracking-enhanced prompt strategy to improve SAM3’s understanding capabilities for tiny and semantic-dominated objects, outperformed the 2nd place by 1.75% in J&F_new.
- The 1st Winner for 5th MeViS-Text Challenge: Engineered an MLLM-guided SAM3-agent pipeline for iterative mask grounding and autonomous semantic refinement, outperformed the 2nd place by 7.91% in J&F.
📝 Publications
* Eauql contribution. # Corresponding author
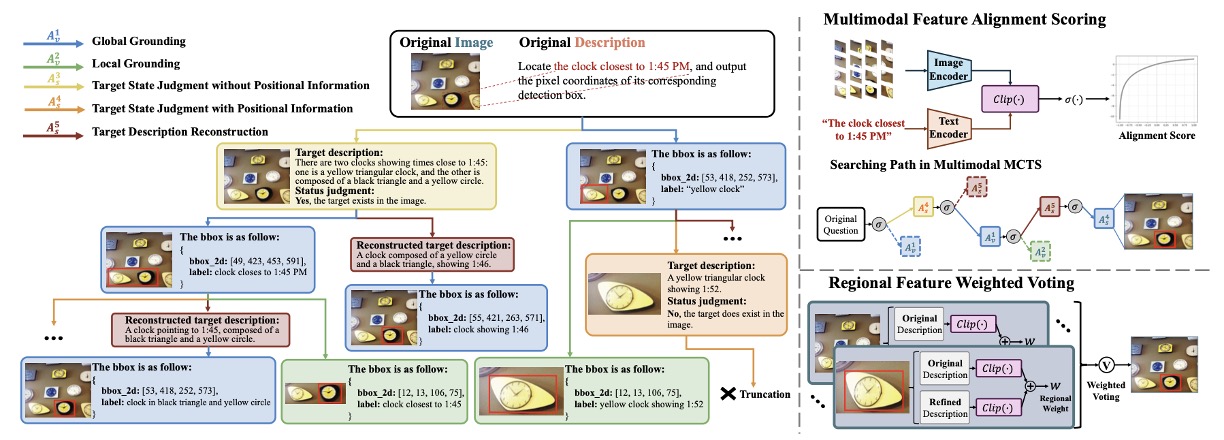
Jinrong Zhang, Zhaoyang Xu, Xusheng He, Xinrui Li, Na Zheng, Jianlong Wu#
First Author, CVPR (CCF-A), 2026
- Revealed the limitations of current MLLMs in pixel-level regional perception and propose a multimodal MCTS-based reasoning framework to overcome this bottleneck, enabling a 7B model to achieve performance comparable to 72B.
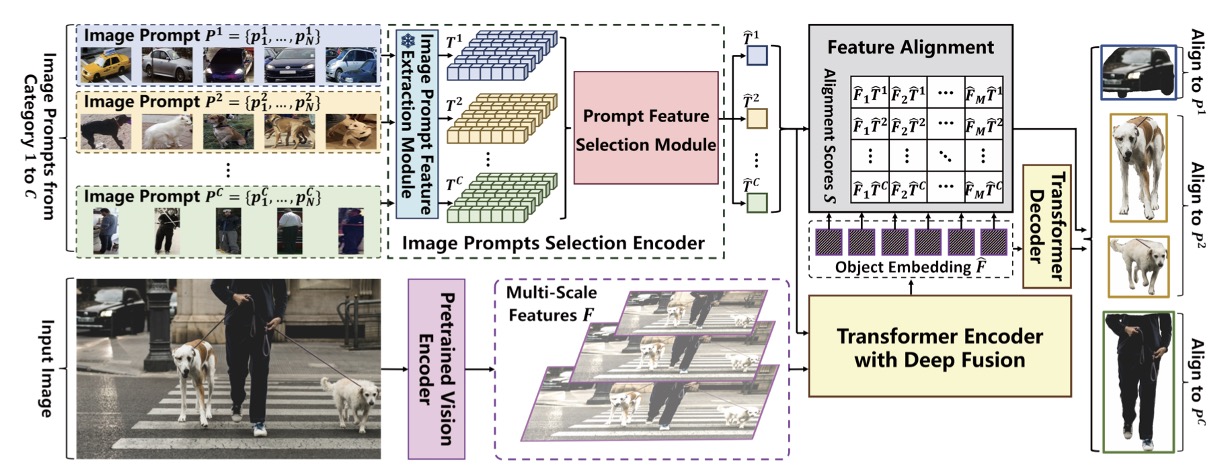
Just a Few Glances: Open-Set Visual Perception with Image Prompt Paradigm
Jinrong Zhang, Penghui Wang, Chunxiao Liu, Wei Liu, Dian Jin, Qiong Zhang#, Erli Meng#, Zhengnan Hu
First Author, AAAI (CCF-A), 2025
- Introduced a novel visual prompts for open-world object detection and segmentation, which bypasses the inherent ambiguity of textual descriptions and achieves enhanced performance and robustness.
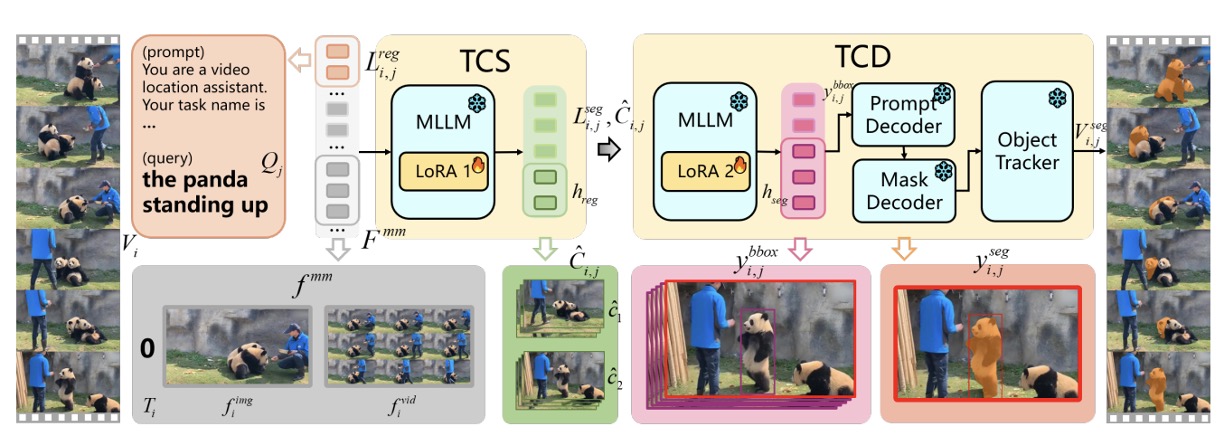
DTOS: Dynamic Time Object Sensing with Large Multimodal Model
Jirui Tian*, Jinrong Zhang*, Shenglan Liu#, Luhao Xu, Zhixiong Huang, Gao Huang
Co-First Author, CVPR (CCF-A), 2025
- Designed DTOS for precise spatio-temporal grounding in MLLMs, utilizing a two-stage temporal-spatial refinement mechanism and task-specific quantitative tokens to accurately locate discontinuous targets while overcoming information loss caused by uniform sampling and natural language ambiguity.
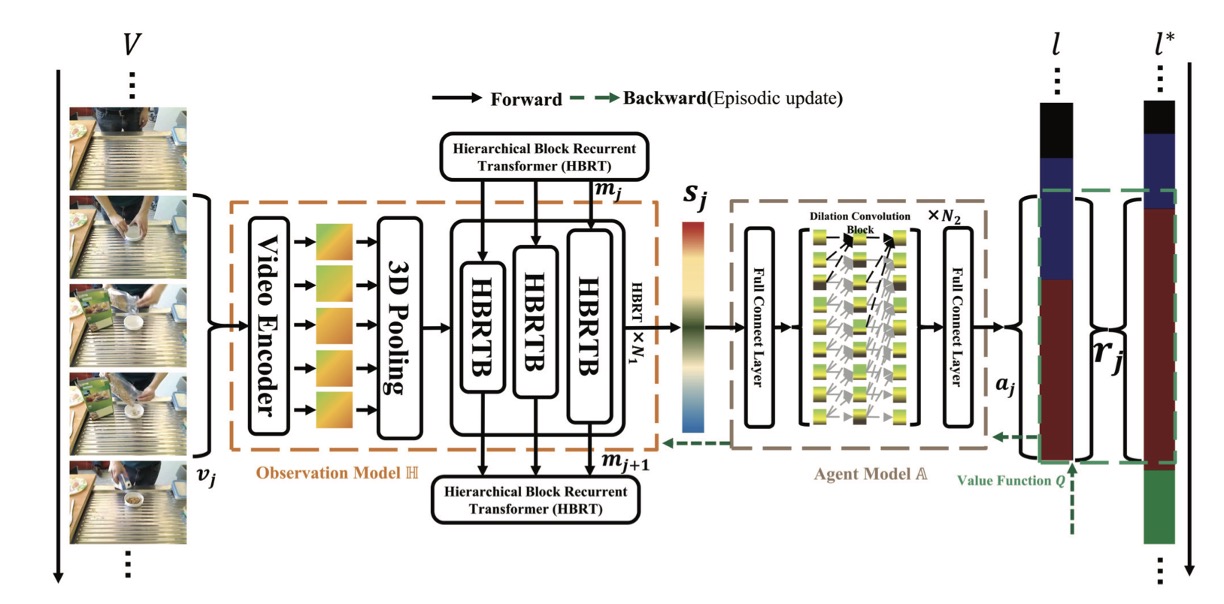
End-to-End Streaming Video Temporal Action Segmentation With Reinforcement Learning
JinRong Zhang, WuJun Wen, ShengLan Liu, Gao Huang, YunHeng Li, QiFeng Li, Lin Feng#
First Author, TNNLS (IF = 8.9), 2025
- Pioneering a streaming video paradigm for temporal action segmentation unlocks ultra-long and online processing capabilities. Analyzing the intrinsic properties of streaming video and introducing a reinforcement learning paradigm successfully bridges the resulting feature gap.
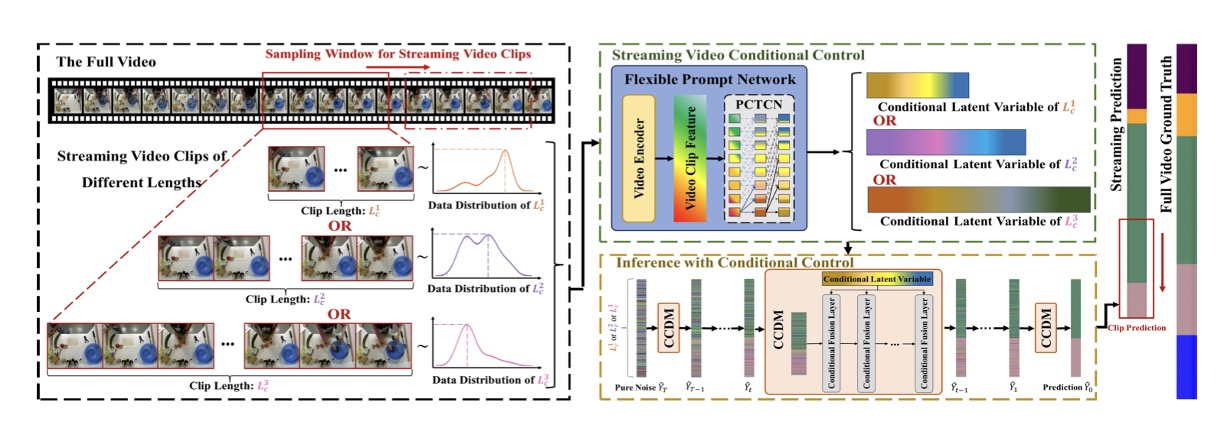
Flexible Streaming Temporal Action Segmentation with Diffusion Models
Jinrong Zhang, Wujun Wen, Shenglan Liu, Sifan Zhang, Yuning Ding, Lin Feng#
First Author, ICME (CCF-B), 2025
- Extending to dynamic streaming video scenarios to evaluate intrinsic feature variations across variable-length clips, and deploying a diffusion model architecture that fundamentally shifts the task paradigm to yield temporal robustness.
🗒️ Others
- Multidimensional refinement graph convolutional network with robust decouple loss for fine-grained skeleton-based action recognition: Sheng-Lan Liu, Yu-Ning Ding, Jin-Rong Zhang, et al. TNNLS 2024.
- 2M-AF: A Strong Multi-Modality Framework for Human Action Quality Assessment with Self-Supervised Representation Learning: Yuning Ding, Sifan Zhang, Liu Shenglan, Jinrong Zhang, et al. ACM MM 2024.
- Cluster-Refined Optimal Transport for Unsupervised Action Segmentation: Shijie Wang*, Jinrong Zhang*, et al. ICASSP 2025.
- Unsupervised Temporal Action Segmentation Based on Wavelet Feature Processing: Xianghan Lin*, Jinrong Zhang*, et al. IJCNN 2025.
🎖 Achievements
- Outstanding Graduate, Dalian University of Technology
- International Underwater Robot Competition, Championship
- The 19th RoboMaster Robotics Competition, Second Prize
- China Robotics Competition (Underwater Robot Operations Project), Second Prize
- Chinese Collegiate Computing Competition, Second Prize