End-to-End Streaming Video Temporal Action Segmentation with Reinforcement Learning
Jinrong Zhang
Abstract
The streaming temporal action segmentation (STAS) task, a supplementary task of temporal action segmentation (TAS), has not received adequate attention in the field of video understanding. Existing TAS methods are constrained to offline scenarios due to their heavy reliance on multimodal features and complete contextual information. The STAS task requires the model to classify each frame of the entire untrimmed video sequence clip by clip in time, thereby extending the applicability of TAS methods to online scenarios. However, directly applying existing TAS methods to SATS tasks results in significantly poor segmentation outcomes. In this paper, we thoroughly analyze the fundamental differences between STAS tasks and TAS tasks, attributing the severe performance degradation when transferring models to model bias and optimization dilemmas. We introduce an end-to-end streaming video temporal action segmentation model with reinforcement learning (SVTAS-RL). The end-to-end modeling method mitigates the modeling bias introduced by the change in task nature and enhances the feasibility of online solutions. Reinforcement learning is utilized to alleviate the optimization dilemma. Through extensive experiments, the SVTAS-RL model significantly outperforms existing STAS models and achieves competitive performance to the state-of-the-art TAS model on multiple datasets under the same evaluation criteria, demonstrating notable advantages on the ultra-long video dataset EGTEA.
Introduction
Streaming Temporal Action Segmentation (STAS) is a task with great potential but has not received enough attention compared to Temporal Action Segmentation (TAS). TAS methods often claim their motivation is to serve practical applications such as intelligent surveillance and smart education. However, there is still no widely recognized TAS method that has been successfully applied in real-world scenarios. The main reason for this limitation is that current TAS methods are confined to offline settings. They rely on pre-extracted multi-modal features of the full videos as input, which involves multi-stage training and complex pipeline processing. In many real-world cases like surveillance or recorded videos, the duration can be several hours or even days. This makes existing TAS methods impractical for real applications due to their unacceptable inference time and memory requirements. Unlike TAS, STAS divides the full video into multiple consecutive clips and streams them into the model. This allows STAS methods to perform online temporal action segmentation for super long videos and online videos with acceptable memory usage and minimal inference latency. In STAS, the model processes one clip of the full video at a time and computes its temporal segmentation. The segmentation results of all video clips are then stitched together to produce the final segmentation for the full video. With the introduction of streaming video inputs and the reduction in duration of streaming video clips, online scenarios such as online teaching and live broadcasting become feasible. STAS not only offers a novel online solution for the field of temporal segmentation but also poses greater challenges.
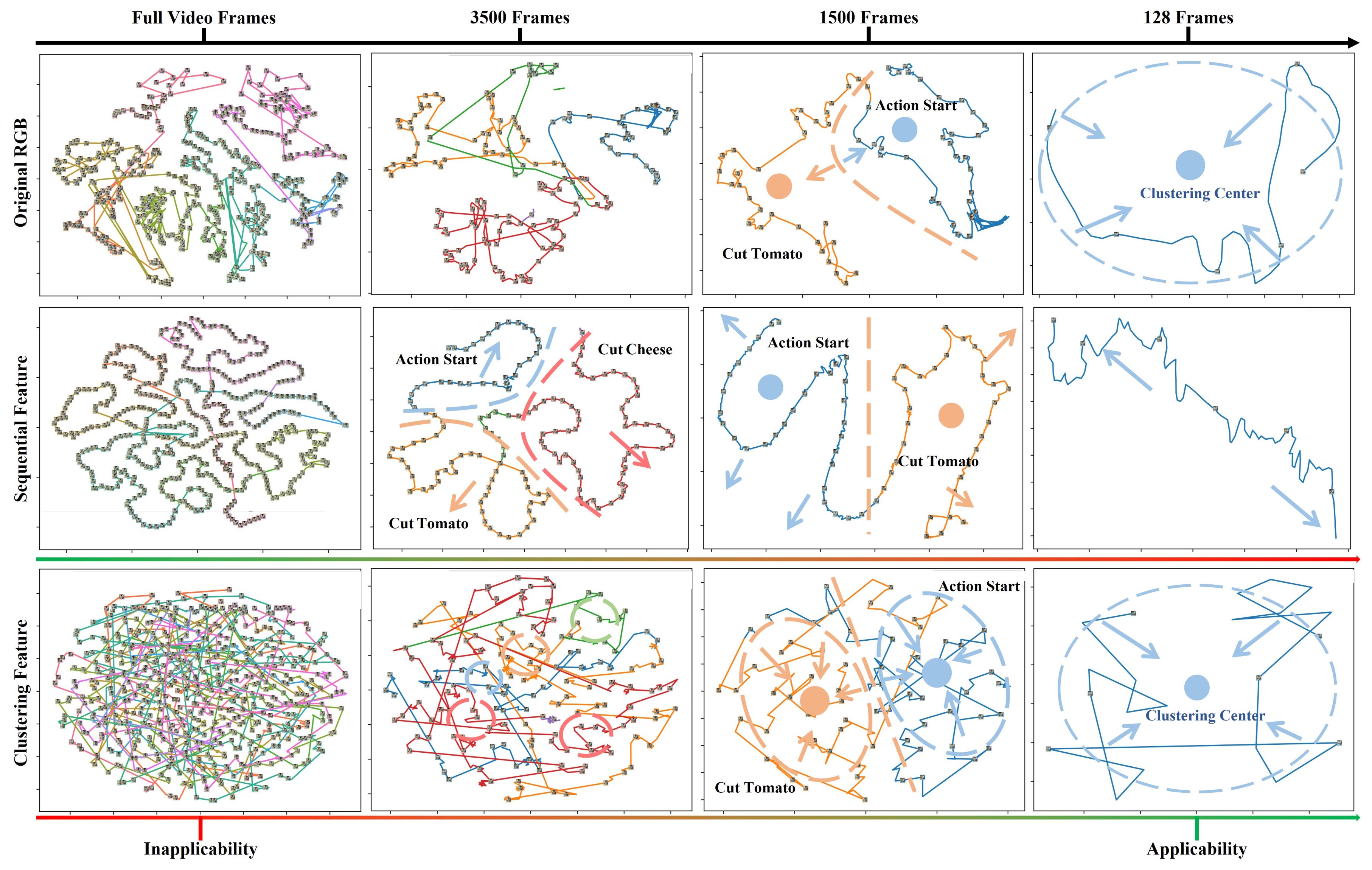
Existing STAS methods are quite scarce and show poor performance. They merely adapt TAS methods to STAS settings without thoroughly analyzing the fundamental differences between STAS and TAS. Although it may seem that the only difference between STAS and TAS is the length of the video processed in each forward pass, there is, a significant difference at the data level. Without proper analysis and corresponding design adjustments to address this difference, further research in this area will face considerable challenges in making meaningful progress. Since the input to TAS models consists of complete videos with long temporal spans, current research typically regards TAS models as sequence-to-sequence transformation systems with specifically designed feature extraction processes , termed the sequence paradigm. However, due to the influence of temporal consistency, the changes in human actions and the environment within videos captured under normal conditions are natural and continuous, which prevents abrupt transitions in human actions and the environment within a short streaming video clip . This means that each frame within a short streaming video clip exhibits high similarity with the others, which causes the video features to shift from the sequence paradigm to the clustering paradigm as the temporal span decreases.
To further study the impact of streaming video data input, we reduce and visualize both the original RGB data of complete videos and different lengths of streaming video clips, alongside the features extracted using the sequence paradigm. Complete RGB videos in high-dimensional space appear as a continuous twisted curve along the time dimension. As video clip length decreases, the sequential characteristics of the original video clips diminish. The features of cropped original video clips, resembling those extracted using a clustering paradigm, suggest better suitability for description by clustering paradigms. The sequential characteristics of sequential features do not change with the reduction in video clip length, which increasingly mismatches the data manifold of the original RGB data. This indicates a significant modeling bias between existing TAS methods and the STAS task. Additionally, the optimization objective for STAS is to maximize the integrity of action segments throughout the video sequence, while the optimization for existing TAS on individual streaming video clips focuses on minimizing frame-level classification loss within each clip. This leads to discrepancies between the gradients calculated by existing supervised optimization methods and the target gradients, a situation we refer to as an optimization dilemma problem. In summary, STAS is a more challenging task that existing TAS methods are ill-equipped to address. The challenges brought by STAS include: (a) the modeling bias severely limits the ability of the model to achieve sequence-to-sequence transformation; (b) the optimization dilemma problem of the training process for STAS models makes the model often falling into the local optimum; (c) streaming data inherently lacks future context information , which has an impact on the integrity of the action segment.
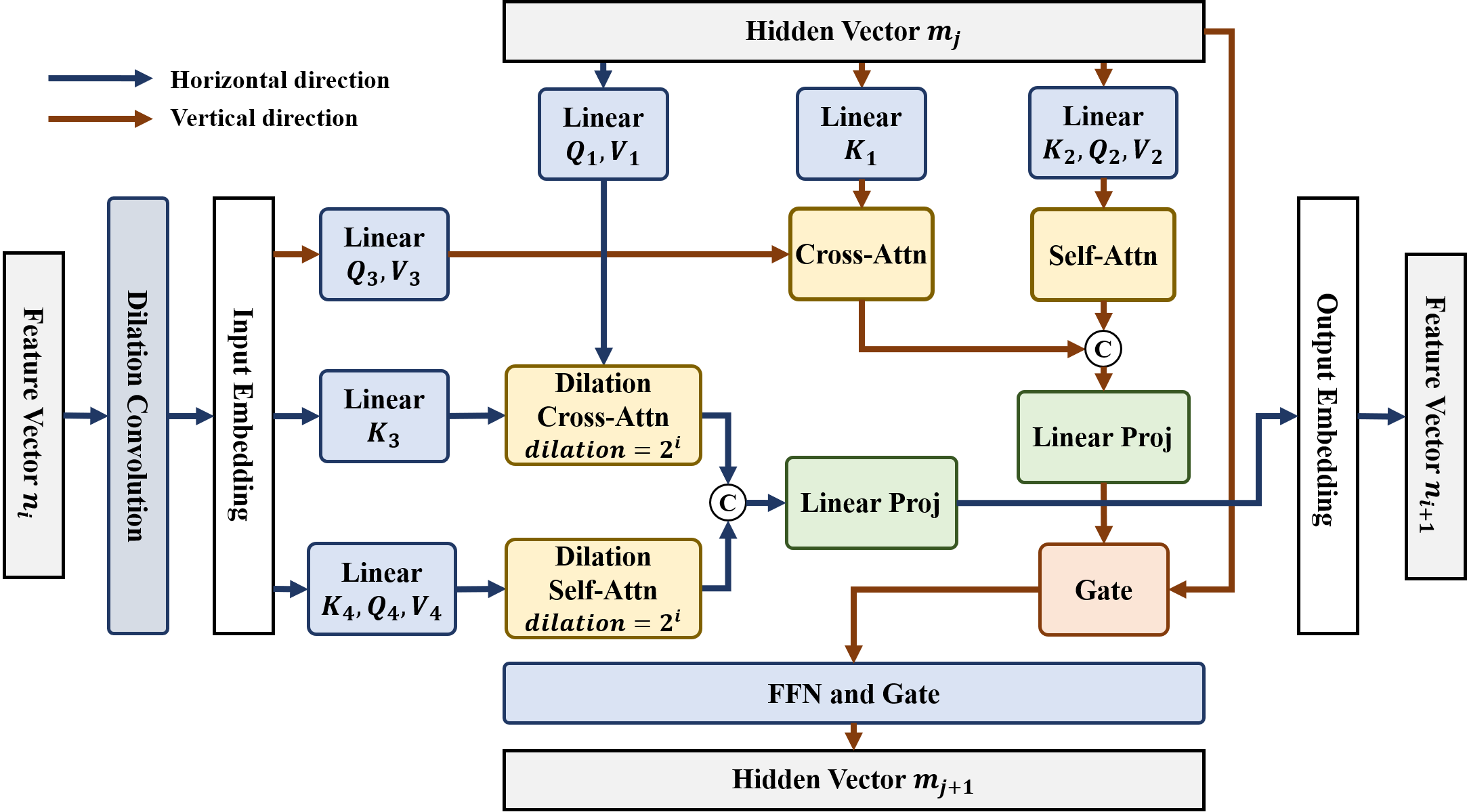
To tackle these challenges, we propose Streaming Video Temporal Action Segmentation with Reinforcement Learning (SVTAS-RL). Specifically, consider the video as an infinite video stream and perform action sequence segmentation directly on a limited length of time step, i.e., a clip of the video each time. At the end, all segmentation results are concatenated. Different from the TAS models, which generates sequential features by sliding window with step size of 1, SVTAS-RL directly extracts clustering features and segments action on current video clips. Our method eliminates modeling bias by aligning the modeling method with the raw data manifold. Similar to offline Automatic Speech Recognition (ASR), the optimum of each module does not necessarily mean global optimum in training STAS. Our method can be trained end-to-end to get rid of tedious training process through limited length of time step, allowing global optimization and mitigating propagation of error. Additionally, it is not feasible to use full-sequence-based approaches such as post-processing or multi-stage methods to avoid optimization dilemma. Moreover, current supervised optimization strategies in TAS task are unable to calculate the corresponding gradient of the optimization objective. Inspired by Reinforcement Learning from Human Feedback (RLHF), Reinforcement Learning (RL) can be used for online training and estimating the gradient of the optimization objective via cumulative expectation to overcome optimization dilemma, which is very suitable for STAS learning. We regard STAS as a sequential decision-making task based on clustering and propose two distinct RL learning strategies to estimate the gradient: Monte Carlo Episodic REINFORCE Learning and Temporal Difference Actor-Critic Learning.
We display the phenomenon of modeling bias for the first time that occurs when TAS models migrate to STAS task. As a solution, we propose SVTAS-RL model that aligns the modeling method with the raw data manifold to eliminate modeling bias.
We are the first to combine RL with STAS to alleviate optimization dilemma by estimating gradient corresponding to the integrity of action of the full sequence. Additionally, we propose two RL learning algorithms suitable for STAS.
Extensive experiments show that SVTAS-RL which our proposed has achieved competitive performance to the State-Of-The-Art (SOTA) model of TAS on multiple datasets under the same evaluation. Moreover, our approach completely outperforms the existing STAS model and shows great performance improvement on the ultra-long video dataset EGTEA.
Task Definition
We regard a video
Method
To address the optimization challenges of the model with streaming video data, we design the model and training process based on the reinforcement learning paradigm, as detailed below. When the proposed SVTAS-RL model is trained using supervised methods instead of reinforcement learning, we refer to it as SVTAS. The observation model
The agent model
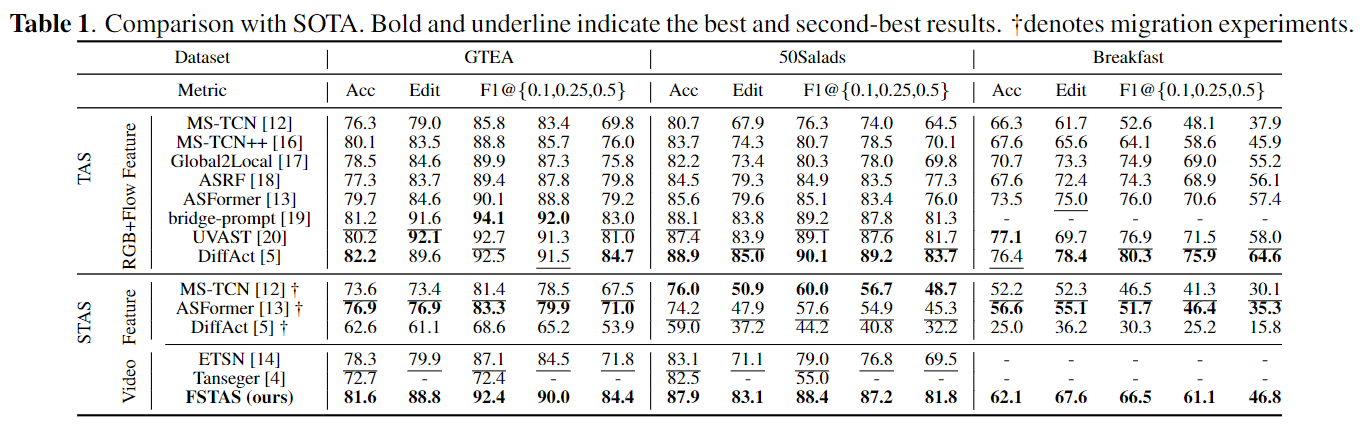
Experiments
We show the comparison results of two segmentation paradigms: TAS and STAS. In addition to existing STAS methods, some TAS methods are transferred to the STAS task for comparison (including ASformer and DiffAct), which show a significant decline in performance after the transfer. We can observe that the end-to-end SVTAS approaches are already very comparable to the SOTA model of the current TAS model. And our method even outperforms the latter on the dataset EGTEA, which indicates that the stream-based approach is better than latter for ultra-long videos action segmentation. Although the SVTAS-RL(MC) approach is lower than the SVTAS-RL(TD) on F1@0.1 and F1@0.25, the former performs better on F1@0.5. Just as the metric in object detection uses an IOU threshold of 0.5 as a more important benchmark for comparison, indicating that the former model is more accurate in integrity of action segment through guidance from RL reward.Breakfast does not perform as expected. We believe that this is caused by the poor quality of the rgb modality for Breakfast dataset.We show some samples from GTEA, 50Salads and Breakfast, and compare their RGB modality and optical flow modality. We can observe that the RGB modality of GTEA and 50Saldas has clear object boundaries. However, it is difficult to distinguish object boundaries even with human eyes in RGB modality of Breakfast. In the optical flow modality, because it will be extracted through the optical flow model, even Breakfast can have good object boundaries and filter out a lot of irrelevant information, which can improve the discriminability of actions . Existing TAS models are mostly multi-modality models that take both RGB modality and optical flow modality as input. This means that even if the RGB modality of samples in Breakfast is extremely poor, the required feature information can still be extracted from optical flow data. However, It is an end-to-end model that our designed SVTAS-RL is, which only takes RGB data as input. This makes the model perform poorly on the Breakfast dataset. If the same RGB modality is used, our proposed model has already exceeded the performance of the full sequence.